1. BERT 언어모델
1.1 BERT 모델 소개
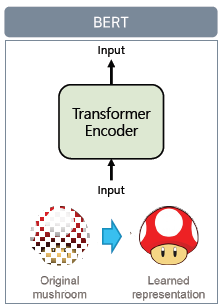
입력된 정보를 다시 입력된 정보를 representation하는 것을 목적
- masked 기술 사용: 원본 복원 어려워짐
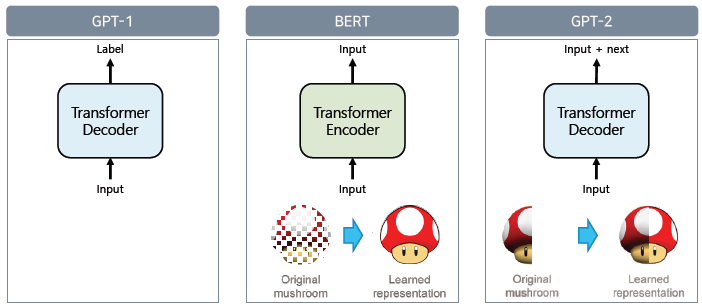
- BERT : 마스크된 자연어를 원본 자연어로 복원
- GPT-2 : 원본 이미지를 특정 sequence를 가지고 자름. 모델은 그 next를 예측
모델 구조

- input layer
- CLS(class label): sentence 1과 sentence 2의 상관관계
- SEP(seperator)
- Transformer layer
- 12개. all-to-all 연결
→ cls 토큰의 출력 vector가 sentence 1과 sentence 2를 포괄하고 있는 어떤 벡터로 녹아든다고 가정: cls 토큰이 sentence 1과 sentence 2를 잘 표현하기 위해 cls 토큰 위에 classification layer를 부착해 pre-train 진행(→ corpus 양 굉장히 많음)
- 12개. all-to-all 연결
Tokenizing
- wordpiece tokenizing: 빈도수 기반
- 첫번째 문장이 선택되고 나면 두번째 문장은 next sentence로 선택되거나 random chosen sentence 50% 확률로 선택
Masked Language Model
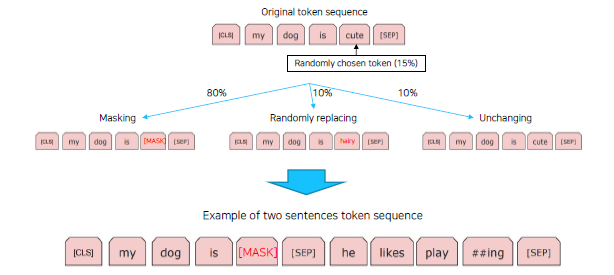
입력 token을 만들고 나면 masking 과정 거침.
(cls와 sep의 special token 제외. 나머지에서 15%의 확률로 random)
NLP 실험 종류

- 단일 문장 분류
- 문장 한개 입력, 어떤 class에 속하냐
- 두 문장 관계 분류
- next sentence 예측
- sentence 1이 sentence 2의 가설
- 두 문장의 유사도 (paraphrase된 거 detect)
- 문장 토큰 분류
- 각 토큰들의 output에 분류기 부착: 어떤 label을 가지게 되는지 분류
- 개체명 인식기
- 기계 독해 정답 분류
- 질문 & 정답이 포함된 문서
- 토큰 내에 정답이 어딘지 찾아내기
1.2 BERT의 응용
- 감성 분석
- 긍정 1, 부정 0
- 관계 추출
- 문장 내 존재하는 지식정보 추출
- entity: 관계 추출의 대상
- 의미 비교
- 두 문장의 의미가 같냐 다르냐
- 전혀 상관없는 주제의 data로 구축되면 다른데서 사용 못하지요?
- 개체명 분석
- 기계 독해
- KorQuAD
1.3 한국어 BERT 모델
ETRI KoBERT
- 형태소 단위로 분리 후, 분리된 것을 바탕으로 word piece 진행
Advanced BERT Model
- entity 정보가 기존 BERT에서는 무시 → entity tag 부착.
- bert의 embedding layer에 entity용 embedding layer 하나 더 부착
우리는 뭘 고민해야 한다? feature가 무엇이 될 것인지..
'부스트캠프 AI Tech > KLUE' 카테고리의 다른 글
| [KLUE] 05. BERT 기반 단일 문장 분류 모델 학습 (0) | 2022.03.23 |
|---|---|
| [KLUE] 04. 한국어 BERT 언어 모델 학습 (0) | 2022.03.23 |
| [KLUE] 02. 자연어 전처리 (0) | 2022.03.23 |
| [KLUE] 01. 인공지능과 자연어 처리 (0) | 2022.03.22 |
댓글